LLM observability is the practice of closely examining how large language models work and perform by collecting data on their inputs, outputs, and internal processes. Arize Phoenix is a powerful tool that provides detailed observability into LLMs, enabling developers to:
- Debug and Identify Issues: Trace LLM operations, track metrics like latency, and analyze model behavior to pinpoint problems.
- Evaluate Performance: Assess model quality against benchmarks, identify areas for improvement, and ensure best practices.
- Fine-Tune Models: Refine model parameters like chunk creation, context extraction, and prompt templates to optimize accuracy and efficiency.
By leveraging Phoenix's tracing, evaluation, and fine-tuning capabilities, developers can iteratively improve their LLMs, leading to more accurate, reliable, and efficient AI applications that drive business success.
Key Features
| Feature | Description |
|---|---|
| Tracing | Track execution metrics, analyze model behavior, and diagnose issues. |
| Evaluation | Use pre-tested templates, ensure data science rigor, and maximize throughput. |
| Fine-Tuning | Analyze performance, brainstorm solutions, and refine models iteratively. |
Arize Phoenix has demonstrated its effectiveness in real-world use cases, such as:
- Debugging LLM deployments by identifying and fixing issues like misconfigured ranking models.
- Optimizing LLM performance by refining parameters like chunk creation and context extraction.
- Improving model accuracy through targeted fine-tuning, as seen in a medical diagnosis tool case study.
As LLMs continue to evolve, LLM observability tools like Arize Phoenix will play a crucial role in shaping the development and maintenance of these powerful models, enabling the creation of more accurate, efficient, and reliable AI applications.
Key Features of Arize Phoenix for LLM Debugging
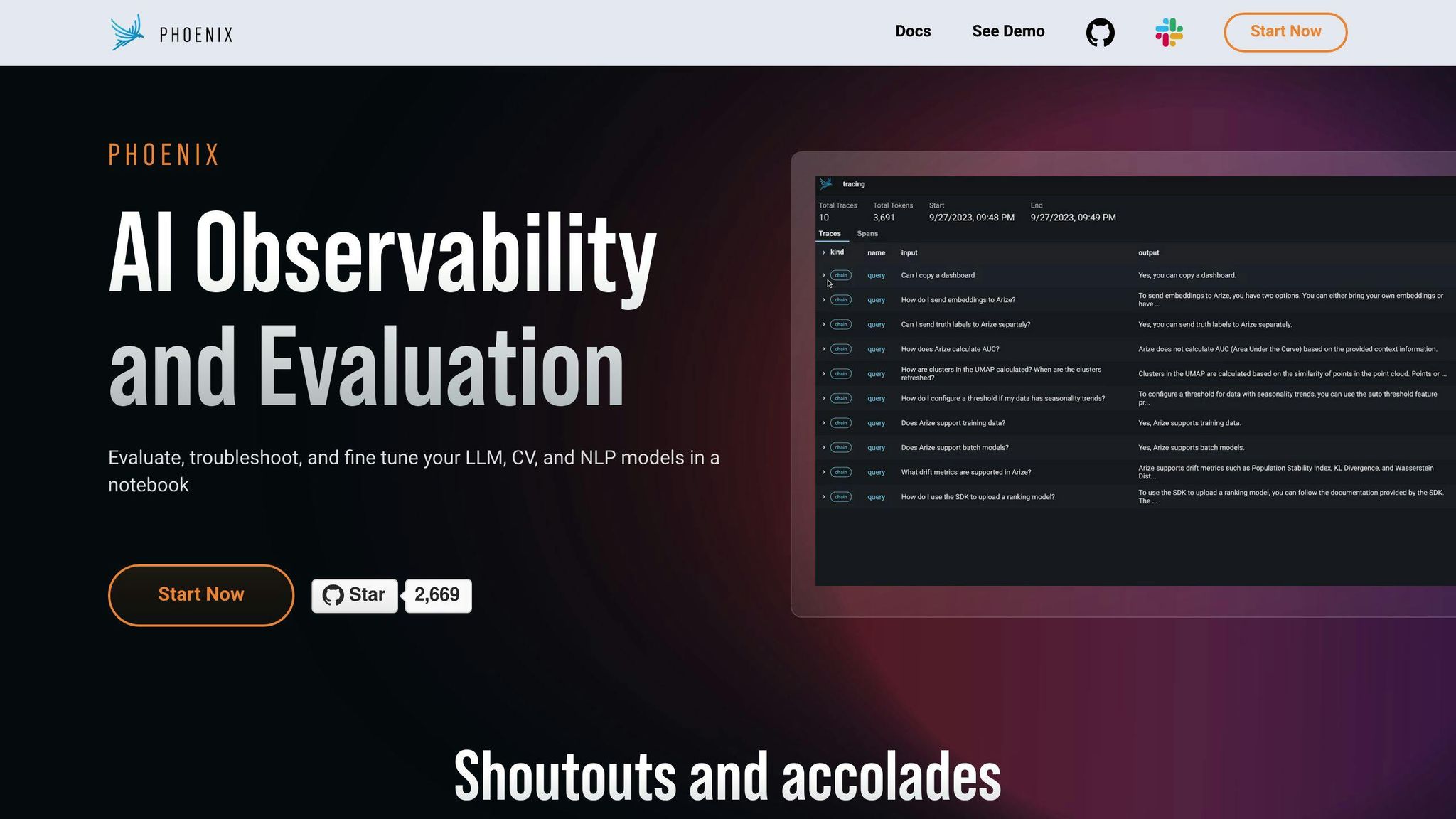
Arize Phoenix offers a range of features that help developers debug and fine-tune their large language models (LLMs) for optimal performance. These features provide deep insights into LLM operations, enabling developers to identify bottlenecks and refine their models for better accuracy and reliability.
Tracing LLM Operations in Phoenix
Phoenix's tracing functions provide detailed visibility into LLM operations, allowing developers to diagnose issues and optimize performance. With Phoenix, developers can:
- Track execution metrics: Examine metrics such as latency and analyze the execution of each step.
- Analyze model behavior: Understand how their models are working and identify areas for improvement.
For instance, Phoenix's tracing capabilities allow developers to track the number of chunks created on the data provided, the context extracted from which pages of data, and the prompt template used.
Evaluating LLMs with Phoenix Tools
Phoenix provides a range of evaluation tools that assist in assessing LLMs against multiple performance benchmarks. These tools enable developers to:
- Evaluate model quality: Assess the quality and performance of their models.
- Identify areas for improvement: Refine their applications for better accuracy and reliability.
Phoenix's evaluation features include:
| Feature | Description |
|---|---|
| Pre-tested eval templates | Use rigorously tested templates to evaluate models efficiently. |
| Data science rigor | Ensure data science best practices are followed in evaluation. |
| Designed-for-throughput processing | Maximize the throughput and usage of API keys. |
Fine-Tuning Models in Phoenix
Arize Phoenix supports the fine-tuning process, enabling developers to refine their models based on actionable data. With Phoenix, developers can:
- Analyze model performance: Identify areas for improvement and refine their applications.
- Brainstorm innovative solutions: Leverage insights gained from evaluation, traces, and spans to improve model performance.
By continuously iterating and improving, developers can achieve better results and enhance the overall performance of their LLM applications.
Tracing LLMs with Arize Phoenix
Understanding Traces and Spans
Tracing is a crucial aspect of LLM observability, allowing developers to gain insights into the inner workings of their large language models. In Arize Phoenix, tracing is achieved through the use of traces and spans. Traces represent the execution path of a request, while spans represent individual components within that execution path. By analyzing traces and spans, developers can identify bottlenecks, optimize performance, and refine their models for better accuracy and reliability.
Real-World Tracing Examples
To illustrate the power of tracing in Arize Phoenix, let's consider a real-world example. Suppose we have a large language model designed to generate responses to user queries. Using Phoenix's tracing capabilities, we can track the execution metrics of our model, including:
- Chunk creation: The number of chunks created on the data provided
- Context extraction: The context extracted from which pages of data
- Prompt template: The prompt template used
This information can help us identify areas for improvement, such as optimizing the chunk size or refining the prompt template to better suit our model's capabilities.
For instance, we can use Phoenix to trace the execution of a query, such as "What are the benefits of using generative AI?" By analyzing the traces, we can see how our model processes the query, including the chunks of data extracted, the context used, and the prompt template applied. This information can help us refine our model's performance, ensuring it provides accurate and relevant responses to user queries.
By leveraging Arize Phoenix's tracing capabilities, developers can gain a deeper understanding of their large language models, identify areas for improvement, and refine their applications for better accuracy and reliability.
Evaluating LLM Performance in Phoenix
Evaluating the performance of large language models (LLMs) is a crucial step in the development cycle. It ensures that LLMs meet the desired accuracy and reliability standards. Arize Phoenix provides a comprehensive evaluation framework to facilitate this process.
Setting Up LLM Evaluations
To set up LLM evaluations in Phoenix, you need to prepare a dataset for evaluation. This dataset should contain input prompts and corresponding ground truth responses. Phoenix supports various evaluation metrics, such as exact-match, toxicity, ARI grade level, and Flesch-Kincaid grade level.
You can specify the model_type argument within the mlflow.evaluate() function to leverage Phoenix's predefined metric sets tailored to specific tasks, such as question-answering, text-summarization, and text models.
Using Golden Datasets for Evaluation
Golden datasets play a vital role in achieving a comprehensive understanding of LLM performance. These datasets provide a standardized benchmark for evaluating LLMs, enabling developers to compare and refine their models.
Phoenix's evaluation framework supports the use of golden datasets, allowing developers to automate the evaluation process and gain insights into their models' strengths and weaknesses.
| Golden Dataset Benefits | Description |
|---|---|
| Standardized benchmark | Enables developers to compare and refine their models |
| Automated evaluation | Allows developers to gain insights into their models' strengths and weaknesses |
| Model refinement | Enables developers to refine their models, ensuring they provide accurate and relevant responses |
In the next section, we will explore how Phoenix facilitates the analysis of LLM retrieval, enabling developers to address retrieval issues and enhance their models' capabilities.
Analyzing LLM Retrieval in Phoenix
Addressing Retrieval Issues
When developing LLM-powered applications, retrieval issues can hinder performance. Arize Phoenix's tracing and evaluation capabilities can help diagnose and address these challenges. By analyzing the retrieval process, developers can identify bottlenecks, optimize chunk creation, and refine prompt templates. This enables them to improve the overall performance and accuracy of their LLM applications.
For instance, Phoenix's tracing feature allows developers to visualize the retrieval process, gaining insights into how their models interact with the data. This can help identify issues such as incorrect chunk creation, inefficient context extraction, or suboptimal prompt templates. By addressing these issues, developers can refine their models, leading to improved response accuracy and reduced latency.
Enhancing LLM Retrieval Capabilities
Arize Phoenix provides features that streamline the process of enhancing LLM retrieval capabilities. By leveraging Phoenix's evaluation framework, developers can benchmark their models against golden datasets, identifying areas for improvement and refining their models accordingly. Additionally, Phoenix's tracing capabilities enable developers to compare different retrieval approaches, selecting the most effective strategy for their specific use case.
Phoenix's support for various evaluation metrics allows developers to comprehensively assess their models' performance. This enables them to identify areas where their models excel and where they require refinement, ultimately leading to more accurate and reliable LLM applications.
| Evaluation Metrics | Description |
|---|---|
| Exact-match | Measures the exact match between model responses and ground truth |
| Toxicity | Evaluates the toxicity of model responses |
| Flesch-Kincaid grade level | Assesses the readability of model responses |
By utilizing Arize Phoenix, developers can unlock the full potential of their LLMs, creating more efficient, accurate, and reliable applications that drive business success.
sbb-itb-f3e41df
Iterative LLM Improvement with Phoenix
Arize Phoenix provides a powerful platform for iterative Large Language Model (LLM) improvement, enabling developers to refine their models and achieve better performance. By leveraging Phoenix's detailed observability data, developers can identify areas for improvement, fine-tune their models, and track the impact of these changes.
Fine-Tuning Steps Using Phoenix
The fine-tuning process involves several steps:
1. Analyze model performance: Use Phoenix's evaluation metrics to assess the current performance of your LLM. 2. Identify areas for improvement: Leverage Phoenix's tracing and evaluation capabilities to pinpoint specific areas where your model can be improved. 3. Refine model parameters: Adjust model parameters, such as chunk creation, context extraction, and prompt templates, based on insights gained from Phoenix. 4. Re-evaluate model performance: Use Phoenix's evaluation metrics to assess the impact of fine-tuning on model performance.
Impact of Model Fine-Tuning
Fine-tuning an LLM can have a significant impact on its performance. By refining model parameters, developers can:
| Impact | Description |
|---|---|
| Improved response accuracy | Fine-tuning can lead to more accurate responses, reducing the likelihood of hallucinations and incorrect information. |
| Enhanced model efficiency | Optimizing model parameters can reduce latency and improve overall model efficiency. |
| Increased model reliability | Fine-tuning can improve the reliability of LLMs, making them more suitable for real-world applications. |
By leveraging Arize Phoenix, developers can iteratively improve their LLMs, achieving better performance and reliability. With Phoenix's detailed observability data, developers can track the impact of fine-tuning and make data-driven decisions to refine their models.
Real-World Use Cases for Arize Phoenix
Debugging LLM Deployments
Arize Phoenix has helped debug complex deployment issues involving LLMs. For example, a leading e-commerce company's LLM-powered chatbot was providing inaccurate responses to customer queries. Using Phoenix's tracing and evaluation capabilities, the development team identified the root cause of the issue - a misconfigured ranking model affecting response accuracy. With Phoenix, the team refined the model parameters, resulting in a significant improvement in response accuracy.
Optimizing LLM Performance
Arize Phoenix has also been used to optimize LLM performance through targeted observability. A popular language translation platform was experiencing latency issues with their LLM-powered translation engine. By using Phoenix's tracing and evaluation features, the development team identified areas for improvement, such as optimizing chunk creation and context extraction. With Phoenix, the team fine-tuned the model parameters, resulting in a significant reduction in latency and improvement in overall model efficiency.
Successful Model Fine-Tuning Cases
Several case studies have demonstrated the effectiveness of Arize Phoenix-guided fine-tuning in improving LLM applications. For instance, a healthcare company developed an LLM-powered medical diagnosis tool. By leveraging Phoenix's evaluation metrics and tracing capabilities, the development team identified areas for improvement and refined the model parameters. As a result, the tool achieved a significant improvement in diagnosis accuracy, leading to better patient outcomes.
These real-world use cases demonstrate the practical value of Arize Phoenix in various LLM development and deployment situations. By providing detailed observability data, Phoenix enables developers to identify areas for improvement, fine-tune their models, and track the impact of these changes.
| Use Case | Description | Result |
|---|---|---|
| Debugging LLM Deployments | Identified and fixed misconfigured ranking model | Improved response accuracy |
| Optimizing LLM Performance | Optimized chunk creation and context extraction | Reduced latency and improved model efficiency |
| Successful Model Fine-Tuning | Refined model parameters for medical diagnosis tool | Improved diagnosis accuracy and better patient outcomes |
These examples showcase the effectiveness of Arize Phoenix in real-world scenarios, highlighting its potential to improve LLM applications and drive business success.
The Future of LLM Observability
The future of LLM observability is promising, with Arize Phoenix playing a key role in shaping the development and maintenance of Large Language Models.
Arize Phoenix in LLM Development
As we've seen, Arize Phoenix has already demonstrated its capabilities in debugging, evaluating, and fine-tuning LLM applications. Its significance extends beyond just being a tool; it represents a new approach to LLM development. By providing real-time insights into model performance, Phoenix empowers developers to create more accurate, efficient, and reliable LLMs.
Advancements in Observability Tools
Looking ahead, we can expect significant advancements in observability tools and techniques. The development of more sophisticated AI models will require the creation of even more powerful observability solutions. We may see the integration of new techniques that enable developers to gain a deeper understanding of their models' decision-making processes.
| Expected Advancements | Description |
|---|---|
| Integration of new techniques | Enable developers to gain a deeper understanding of their models' decision-making processes |
| Real-time data analytics | Enhance the capabilities of observability tools |
| Machine learning algorithms | Further improve the performance of observability tools |
By embracing the future of LLM observability, we can unlock the full potential of Large Language Models and create a new generation of AI-powered applications that transform industries and improve lives.
FAQs
What is LLM observability with Arize?
LLM observability with Arize is a solution that helps developers understand how their large language models work and perform. It collects important information about the model's inputs, outputs, and internal processes. This data is used to identify and fix issues, fine-tune models, and improve performance.
How does Arize support LLM development?
Arize provides a comprehensive observability solution that empowers developers to:
- Collect and analyze responses and user feedback
- Identify areas for improvement
- Fine-tune their models for better accuracy and reliability
By using Arize, developers can create more efficient and reliable LLMs that drive business success.
What are the benefits of using Arize for LLM observability?
The benefits of using Arize for LLM observability include:
| Benefits | Description |
|---|---|
| Improved model accuracy | Identify and fix issues, fine-tune models for better performance |
| Enhanced model reliability | Create more efficient and reliable LLMs |
| Faster development cycles | Reduce development time and costs |
| Better decision-making | Make data-driven decisions with actionable insights |
By leveraging Arize for LLM observability, developers can unlock the full potential of their large language models and create more accurate, efficient, and reliable AI applications.
